 NuDoq: A lightweight .NET XML Documentation API
NuDoq: A lightweight .NET XML Documentation API
A standalone API to read and write .NET XML documentation files and optionally augment it with reflection information.



NuDoq provides a simple and intuitive API that reads .NET XML documentation files into an in-memory model that can be easily used to generate alternative representations or arbitrary processing. If the read operation is performed using a .NET assembly rather than an XML file, NuDoq will automatically add the reflection information to the in-memory model for the documentation elements, making it very easy to post-process them by grouping by type, namespace, etc.
NuDoq leverages two well-known patterns: the Visitor pattern and the Composite pattern. Essentially, every member in the documentation file is represented as a separate “visitable” type. By simply writing a NuDoq Visitor-derived class, you can process only the elements you’re interested in.
NuDoq can read documentation files from any .NET assembly, which are most commonly located alongside the binary.
How to Install
NuDoq is a single assembly with no external dependencies whatsoever and is distributed as a NuGet package. It can be installed issuing the following command in the Package Manager Console:
PM> Install-Package NuDoq
Usage
The main API is DocReader, which you can use to read an XML documentation file, or an assembly, in which case the XML file alongside the assembly location will be read and augmented with reflection information about types and members:
var members = DocReader.Read(typeof(MyType).Assembly);
You can then directly enumerate the members and their elements, but this is tedious and would involve a lot of if/switch statements to account for all the various types of elements and their nesting. This is why the main consumption is though a visitor. If you are not familiar with the pattern here is a good overview.
Essentially, you create a visitor and then override/implement methods for the relevant element kinds you’re interested in.
Here is a sample visitor that would render markdown for the given nodes:
public class MarkdownVisitor : Visitor
{
TextWriter output;
public MarkdownVisitor(TextWriter output)
=> this.output = output;
public override void VisitMember(Member member)
{
output.WriteLine();
output.WriteLine(new string('-', 50));
output.WriteLine("# " + member.Id);
base.VisitMember(member);
}
public override void VisitSummary(Summary summary)
{
output.WriteLine();
output.WriteLine("## Summary");
base.VisitSummary(summary);
}
public override void VisitRemarks(Remarks remarks)
{
output.WriteLine();
output.WriteLine("## Remarks");
base.VisitRemarks(remarks);
}
public override void VisitExample(Example example)
{
output.WriteLine();
output.WriteLine("### Example");
base.VisitExample(example);
}
public override void VisitC(C code)
{
// Wrap inline code in ` according to Markdown syntax.
output.Write(" `");
output.Write(code.Content);
output.Write("` ");
base.VisitC(code);
}
public override void VisitCode(Code code)
{
output.WriteLine();
output.WriteLine();
// Indent code with 4 spaces according to Markdown syntax.
foreach (var line in code.Content.Split(new[] { Environment.NewLine }, StringSplitOptions.None))
{
output.Write(" ");
output.WriteLine(line);
}
output.WriteLine();
base.VisitCode(code);
}
public override void VisitText(Text text)
{
output.Write(text.Content);
base.VisitText(text);
}
public override void VisitPara(Para para)
{
output.WriteLine();
output.WriteLine();
base.VisitPara(para);
output.WriteLine();
output.WriteLine();
}
public override void VisitSee(See see)
{
var cref = NormalizeLink(see.Cref);
output.Write(" [{0}]({1}) ", cref.Substring(2), cref);
}
public override void VisitSeeAlso(SeeAlso seeAlso)
{
var cref = NormalizeLink(seeAlso.Cref);
output.WriteLine("[{0}]({1})", cref.Substring(2), cref);
}
string NormalizeLink(string cref)
=> cref.Replace(":", "-").Replace("(", "-").Replace(")", "");
}
And you would use it as follows:
var members = DocReader.Read(typeof(MyType).Assembly);
var visitor = new MarkdownVisitor(Console.Out);
// This would traverse all nodes, recursive, and Visit* methods appropriately
members.Accept(visitor);
There is also an XmlVisitor in the library that can generate the XML doc file from the in-memory model too, if you want to create (or modify) the documented members.
There is also a built-in DelegateVisitor which is useful to traverse the entire tree to process only specific nodes. For example, if you wanted to validate all the links in see/seealso elements, you’d use something like:
var members = DocReader.Read(typeof(MyType).Assembly);
var visitor = new DelegateVisitor(new VisitorDelegates
{
VisitSee = see => ValidateUrl(see.Href),
VisitSeeAlso = seealso => ValidateUrl(seealso.Href),
});
members.Accept(visitor);
Model
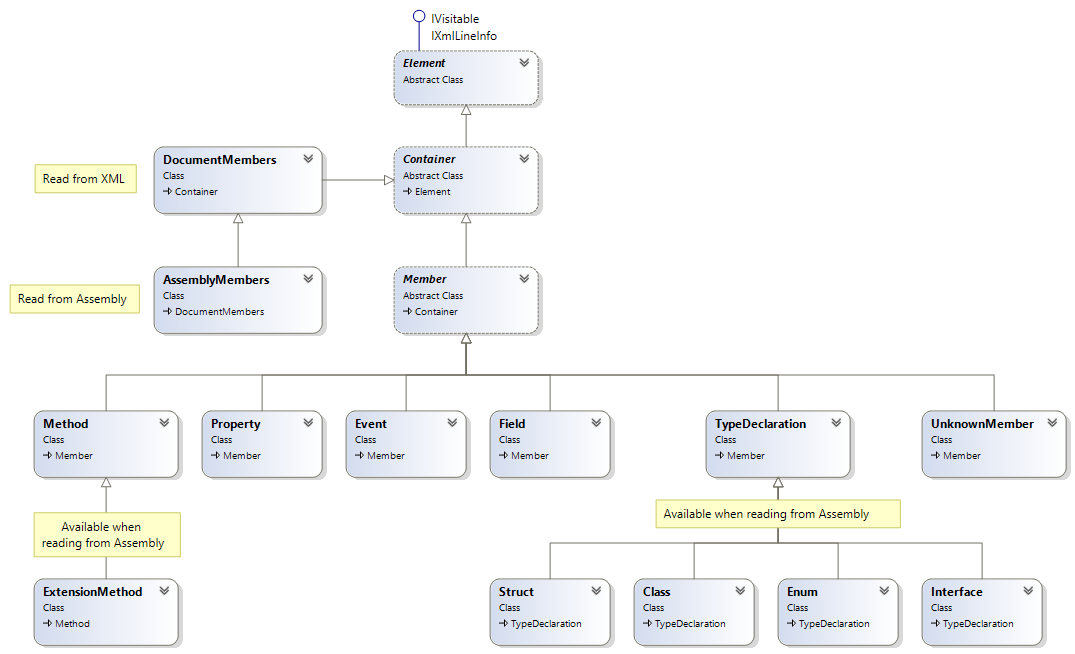
Given the main API to traverse and act on the documentation elements is through the visitor pattern, the most important part of the API is knowing the types of nodes/elements in the visitable model.
There are two logically separated hierarchies of visitable elements: the members (like the whole set read by the DocReader, a type, method, property, etc.) and the documentation elements (like summary, remarks, code, etc.).
The following is the members hierarchy:
And this is the supported documentation elements hierarchy:
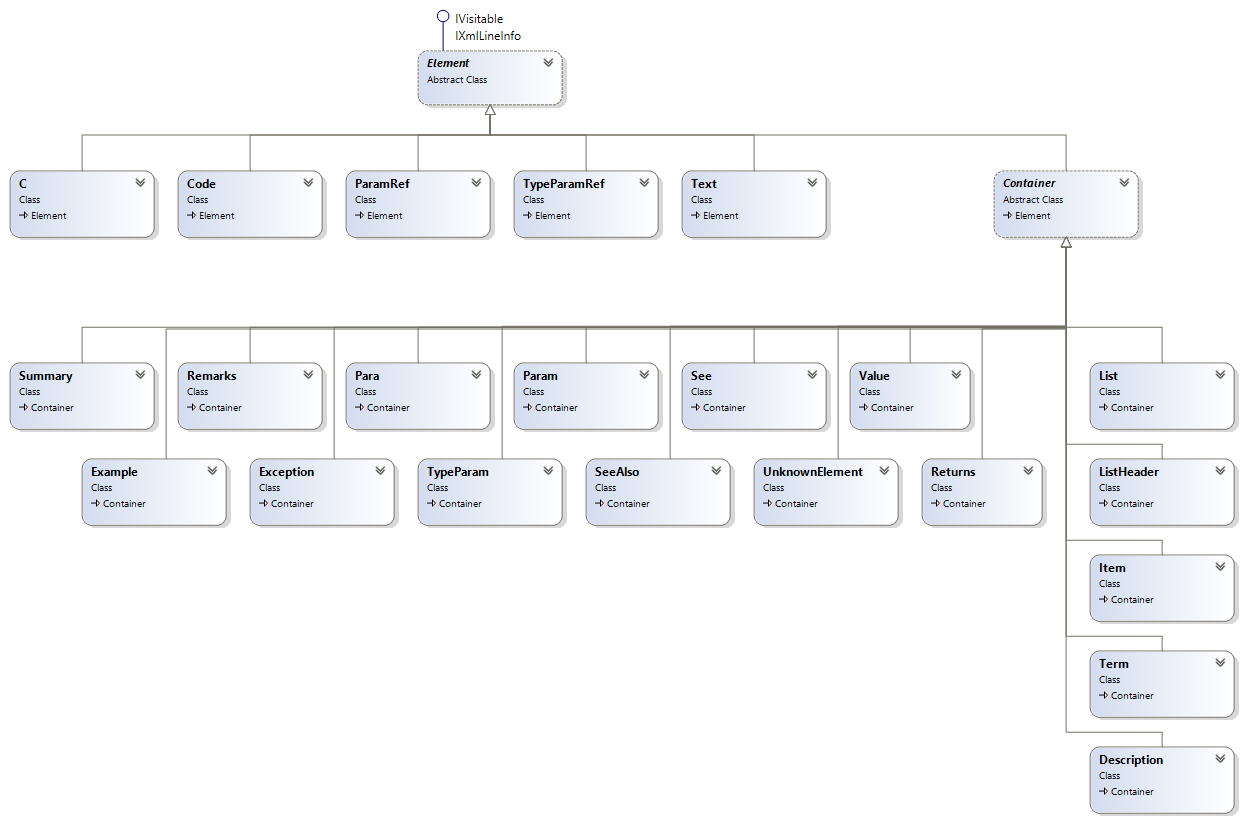
Note that at the visitor level, both hierarchies are treated uniformly, since they all ultimately inherit from Element. In this fashion, you can have one or multiple visitors processing different parts of the graph, such as one that processes members and generates individual folders for each, and one for documentation elements that generate the content.
Sponsors










](https://github.com/Mrxx99)
[
















